
June 28, 2018 | InBrief
Driving business value and efficiency using Kafka and Docker
Driving business value and efficiency using Kafka and Docker
Tracking user behavior is a must for all consumer facing applications. You want to know how the user is interacting with your user interface (UI) and how they feel about the user experience (UX). Let’s say an e-commerce site user is having difficulty navigating to the checkout page. Having immediate knowledge of this troubled user allows you to offer assistance in real time, perhaps in the form of a help bubble on the page. If the user is struggling and calls a customer service representative (CSR), the agent would be able to pull up exactly what the user was doing and easily troubleshoot the issue. In the long term, if you learn that multiple users run into the same issue, a UI redesign can help alleviate user confusion and prevent future customers from navigating away from the site in frustration.
All user interactions can be tracked by some simple business logic added to the code behind a web application, but what do we do with this data? And what if we have millions of events every day? Even worse, what if we have millions of events every few hours, or even every few minutes? Enter stage right: Kafka.
Originally created in 2011 by LinkedIn and then handed off to Apache for dedicated development, Kafka is a distributed streaming platform. From the official Apache site, a streaming platform does three things:
-
“Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.”
-
Kafka can add or remove messages from a stream in a queue fashion.
-
-
“Store streams of records in a fault-tolerant durable way.”
-
Messages are placed on the stream fault-free every time.
-
-
“Process streams of records as they occur.”
-
Events that happen are processed and put on the stream in real time.
-
Kafka is used by a handful of commercial giants, including: LinkedIn, Yahoo, Twitter, Netflix, Spotify, Uber, and PayPal. Each of these companies uses Kafka for different aspects of their applications, but common use cases include collecting and moving all the logs for multiple applications into a single location, or forming the foundation for an event-driven architecture (EDA). A list of common use cases can be found on the Apache Kafka website.
The specific use case mentioned earlier was website activity tracking, which is the one we will be discussing further. A custom built Kafka solution was the right fit for our situation because of the sensitivity of the data we needed to stream. Our custom solution allowed the client to hand pick which data would be streamed while refusing to transmit sensitive information like SSN or passwords. Kafka also allows for encryption of data both inside and outside of the streaming infrastructure, making it not only reliable but secure as well. The premise of this blog will be an example of how to implement a containerized (using Docker) data streaming architecture using Kafka in conjunction with the Kafka-based Confluent Platform. The general plan of attack is as follows:
-
Set up all components of Kafka infrastructure (Kafka, ZooKeeper, Schema Registry, REST Proxy, Kafka Connect, data stores) across multiple servers.
-
Track page loads, button clicks, exceptions, and any other relevant events across the web portal.
-
Publish the events to Kafka.
-
Push the events from Kafka into data stores.
Docker, a platform that allows developers to build and run distributed applications, is used to containerize all the infrastructure components listed above. While a single server setup is possible, multiple servers are advised to increase the availability of the servers and allow for a higher throughput. To run a Docker container across multiple servers, it must be in swarm mode to connect the machines and have them function as a single body. For a simpler implementation, you could have one server run the Kafka components and another run the data store components. For a more complex, but more reliable setup you could create an architecture similar to the diagram below. Separating the different Kafka components onto different servers increases the throughput of each component and increases the reliability of the application. If a single node in the server setup drops from the network, Docker Swarm will automatically reallocate resources on a different server and redeploy the components to a new location, further increasing the reliability and availability of your application.
Assuming the servers have been provisioned with Docker, the next step is to configure the different pieces of Kafka. Spinning up the containers with a well-crafted docker-compose.yml file will take care of installing and configuring each component. This file will deploy all of the component images across the servers that are part of the swarm. Below is an example architecture diagram showing how a Kafka message can be guided through a configuration with multiple servers (each box indicates a different server in the setup).
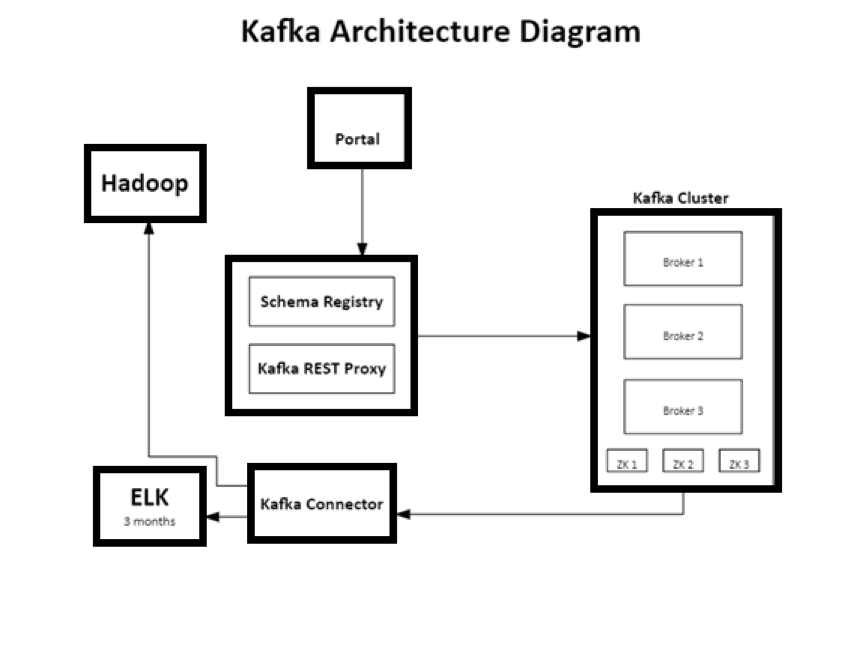
Once the streaming infrastructure is up and running, we can focus on tracking user events on the web portal. The goal is to capture all pertinent information about an event and bundle it up into a JavaScript object. While “pertinent” is dependent on your application, the object should capture basic information such as which button/toggle/input was clicked, a timestamp, URL, IP address. As far as application-specific information, a good data point to capture is a user’s identifier if your website involves a login system. With the fully formed JavaScript object, you then POST it to the Kafka REST Proxy, which simply acts as a RESTful API to send messages to Kafka.
After being sent to the REST Proxy, the message hits the Schema Registry, where the message’s formatting is checked against the current version of the schema. If the message matches the format defined in the schema, the message is then sent to the Kafka data stream and placed into the corresponding topic. All Kafka messages will reside inside a topic, and topics are generally split up by the type of message that is sent. This allows topics to only contain information that is relevant to the type of message that is sent (i.e. exception messages vs. user interaction messages).
Now that the messages are being sent to Kafka and they are placed into the correct topics, the only thing left to incorporate is the data storage piece. Confluent, the team of developers who maintain Kafka, provide an entire suite of Kafka related enterprise tools. There are tools for monitoring Kafka clusters, management tools, and even a collection of specific connectors for popular applications that connect to Kafka. In our case, we are using Elasticsearch for short-term storage and Hadoop Distributed File System (HDFS) for permanent storage, both of which have Kafka Connect connectors out of the box. Other options outside of Kafka Connectors are available to push messages into data stores as well, including (but not limited to): custom AWS Lambda functions, Azure functions, or even writing your own service. Once configured (and assuming the data stores have been properly set up), data will be pushed onto the stream and will be simultaneously pushed into both data sinks.
At this point, the entire application will have full event tracking coverage. Every button click, text input, and page load will be streamed to Kafka and logged into two data stores. Adding this sort of Kafka implementation to an organization’s technology ecosystem adds a variety of different values:
-
Tracked web portal events enable analytics to determine issues encountered by members and motivate customer experience improvements.
-
Events in data stores available immediately to provide customer assistance and indefinitely to retain a user’s full interaction history.
-
Multi-server Docker configuration will allow for a higher throughput of data in Kafka to handle more traffic on the web portal while maintaining portability.
The numerous benefits afforded by such an infrastructure can be applied to other domains within an organization with minimal additional effort to curate the best possible experience for users. Our technology experts have experience in assisting clients in building out their technology strategies to further align with consumer values. If you would like to learn more about designing or implementing data streaming architectures similar to Kafka, feel free to reach out to us for more information.

